

Data is the foundation of modern companies, big and small, and being able to work with data is essential to a steady career as a software developer. The promise of learning programming in a "Data-Focused" way means that as long as customers and users are generating data, you can be gainfully employed helping them unleash that data's potential for their businesses.
So, a few months ago Inoxoft organized a course “Data-Focused Programming (with Python, AI/ML)”, mentored by our CTO, Brad Flaugher. A 10-week course covered the full stack of technologies available to the modern programmer, with a specific focus on long-supported and much-loved open-source technologies like Python, C, and UNIX.
To finish the course students had to create innovative machine learning projects and now want to share with you a couple of them.



Python Machine Learning Projects
We didn’t give any ideas of machine learning projects for students, but guided them and hinted at what was going to be innovative these days. They created each of these models from scratch: out of sheer interest and smart pursuit of ML technology. And on a variety of interesting topics: from Covid related projects to ml projects connected to price prediction.
COVID-19 X-ray detection model
One of the most relevant and useful machine learning projects was the attempt to create a Covid-19 detection model. But let’s start with the basics: what is object detection? How does it work? And what for? Object detection is a subfield of a computer vision technique that allows us to identify and locate objects in an image or video. Application includes:
- Autonomous and Assisted Transportation (automated fine issuing)
- Medical imagery analysis
- Sports performance tracking and analysis
- Agriculture monitoring
- Retail and manufacturing support
- Crowd control and face recognition
- Military use
The goal of the object detection model is to output the bounding boxes, the class of the bounding boxes, and the probability score for that prediction.
There are three archetypes of Meta Architectures of object detection model.

- SSD – a model that is based on classification as it analyzes the whole image at once, trying to indicate if there is an object.
- Faster RCNN – tends to be more on the side of classification due to its architecture: it scans an image and classifies each of them.
- R- FCN – a mix of both.
The model itself
The plan was to do a model that detects and localizes COVID-19, to help doctors to provide a quick and accurate diagnosis. First of all the team classified and detect different categories of pictures.

Currently, COVID-19 can be diagnosed via PCR test, but the problem with this method is that it takes from a few hours to a few days to detect the virus’s genetic material and receive results. On the other hand, there is a possibility to use an X-ray that potentially can give a result within a few minutes. There are a lot of guidelines that help radiologists differentiate Covid from other viruses. Moreover, other doctors can also take advantage of X-rays to localize the disease.
The model works in a way that you can upload an (X-ray) image, the model recognizes the class of the image and gives results based on the picture (e.g. Negative/ 38% typical pneumonia, 22% – indeterminate).
Challenges the team faced:
- Small dataset (6334 images)
- Problematic images in the dataset (blurred, exposed, images with foreign objects)
- The most wanted (Covid related) atypical class had the smallest percentage of all the images in the dataset

The team tried the following approaches to see what they can get from such a data set:
- TensorFlow Object Detection API (with all the benefits it can offer, the particular approach didn’t give high accuracy)
- Keras, CNNs

The team trained the model on the data set and got 47% of accuracy (see the e.g) and used a pre-trained model (VGG19 – Visual Geometry Group)
Poem analyzer
Among other machine learning projects in python was the one that aimed to analyze poems. The team created a couple of models.
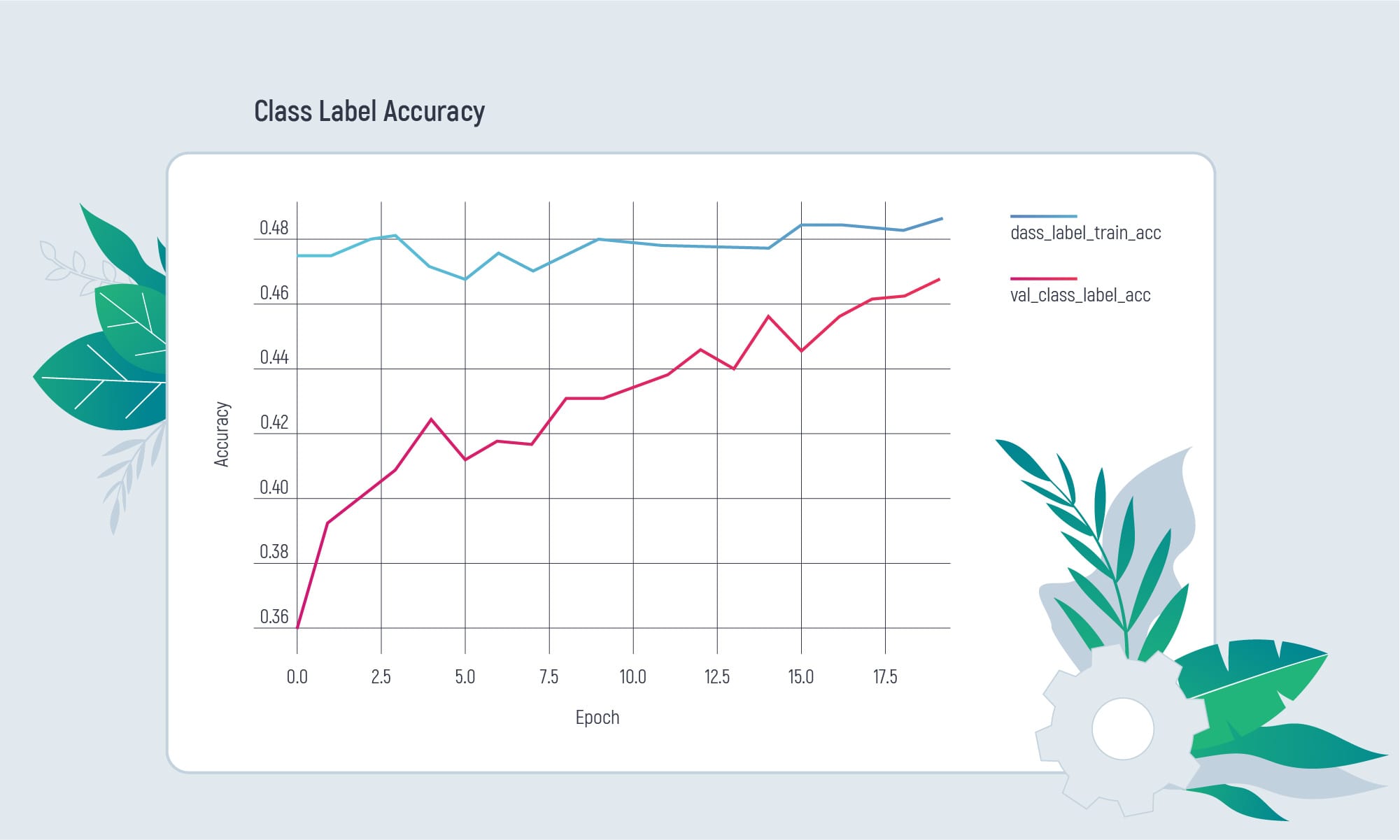
The first one predicts one or several topics which were addressed in the poem.
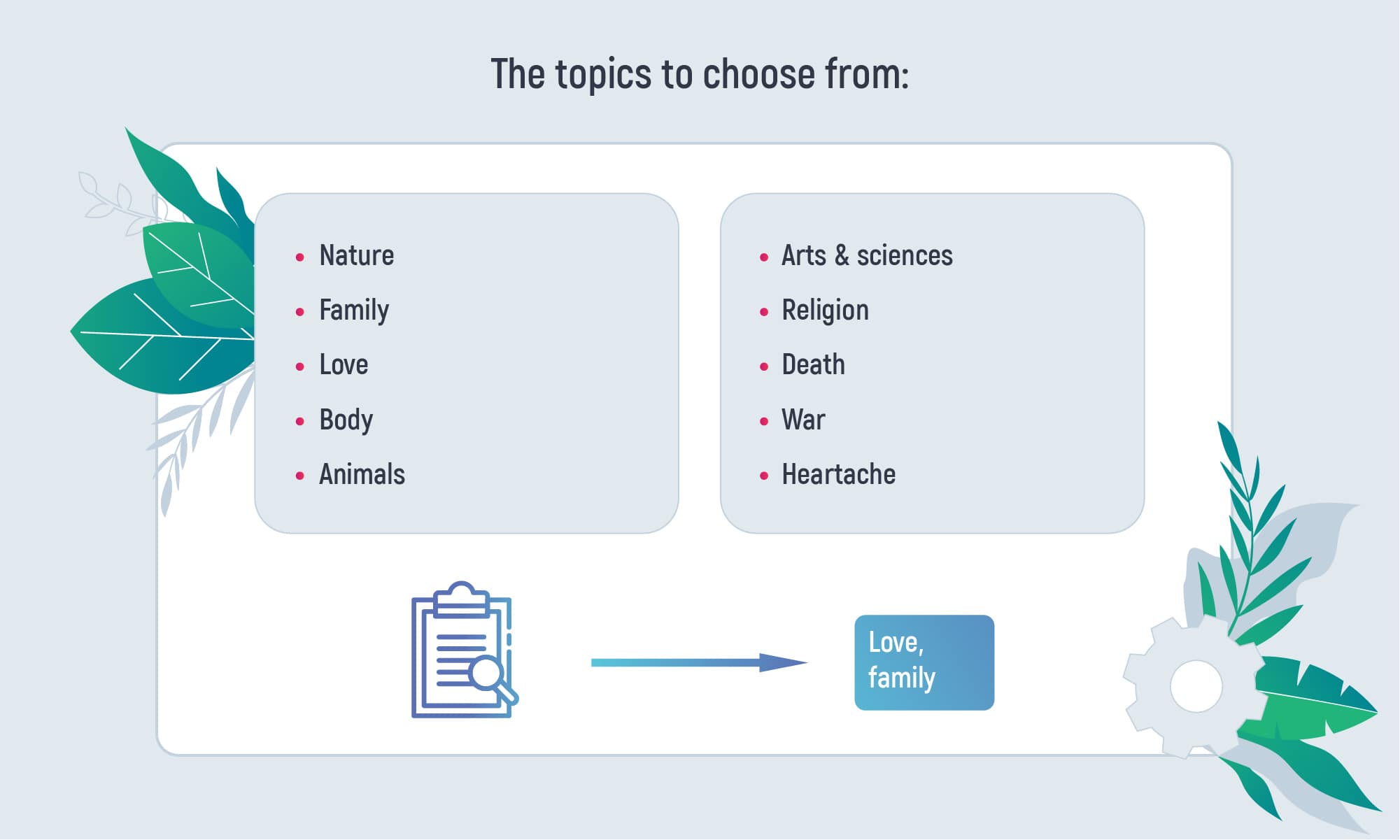
The second model predicts the year the poem was written. The topic model gives about 50% accuracy. The year model has a mean absolute error of 26 years. How does it work?
- User types the title and text of the poem

- After submitting it, the user receives prediction results

What the process looked like? Steps included
- Data sources
- Dataset creation steps
- Websites scraping
- Data consolidation
- Data merging
After scraping the websites, the team merged collected data, cleared data from NaN’s, and removed duplicated rows from the dataset. All the copies of poems were removed and all similar labels were united. The same labels led to the unified names. E.g.
So, among the labels, the team got 153 labels from 281 poems.
Initial dataset lookup included

Also, the team took specific text into consideration: the max length was set to 150 words, shorter texts were dropped and longer – cut.
Preprocessing
To fit text to the model there is a need to convert it to numbers. The following steps are needed to get the result:
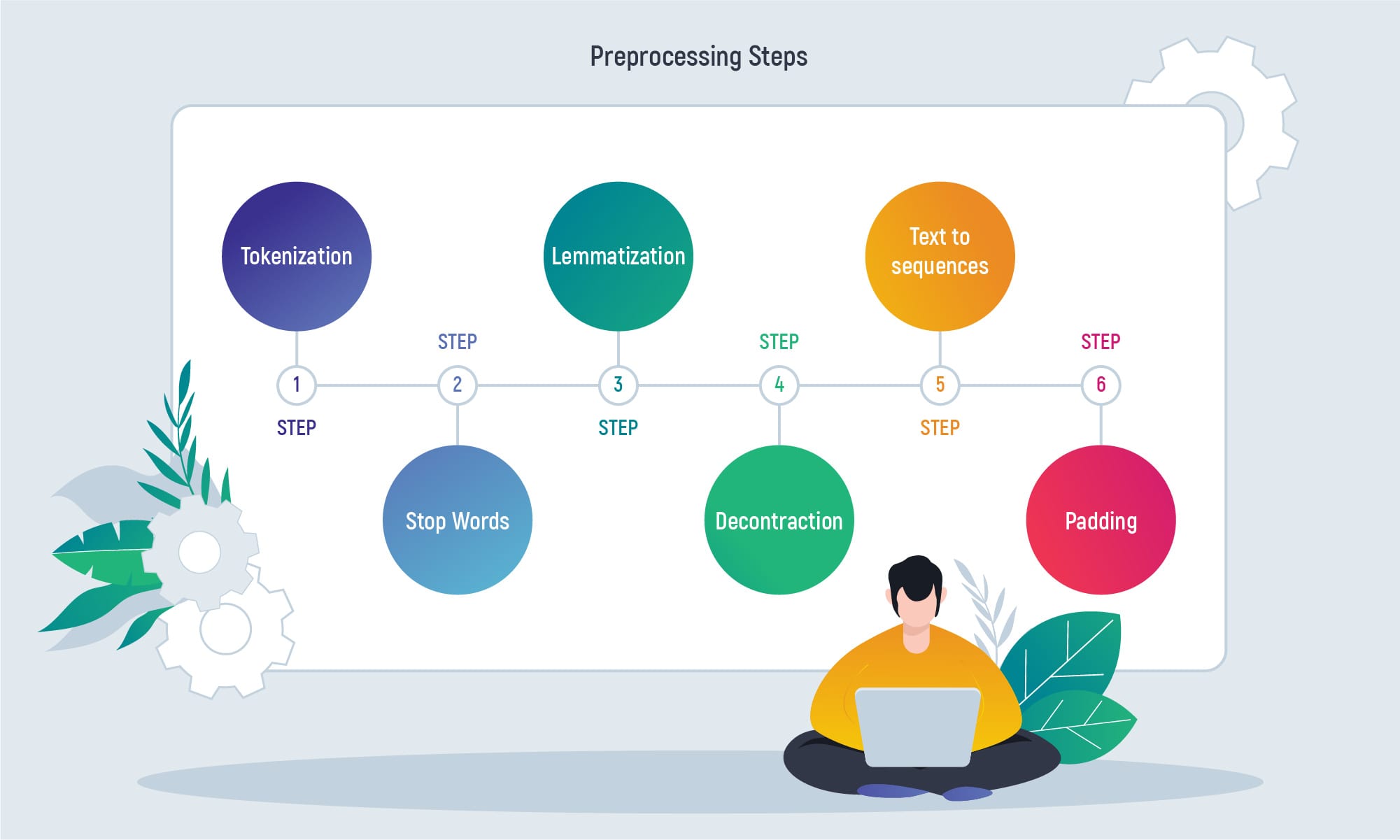
1. Tokenization – the process of converting text into separate elements (called tokens).

2. Removing useless words (“stop” words) that have no value and serve only to connect the words that make sense. E.g.

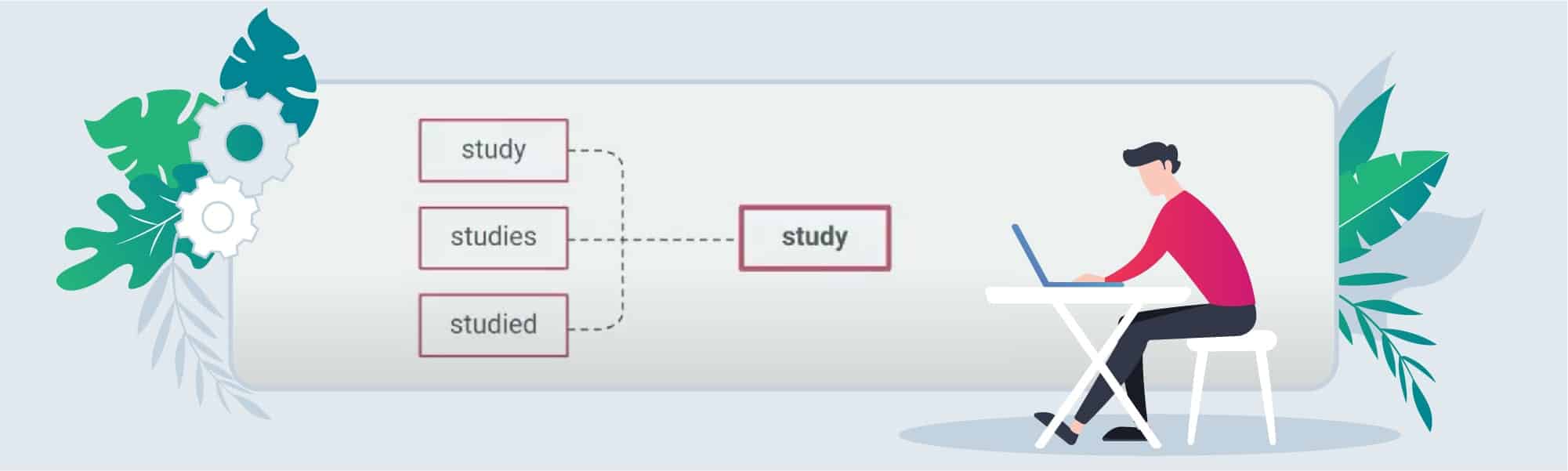
3. Lemmatization means treating different forms of words as a single word. E.g.
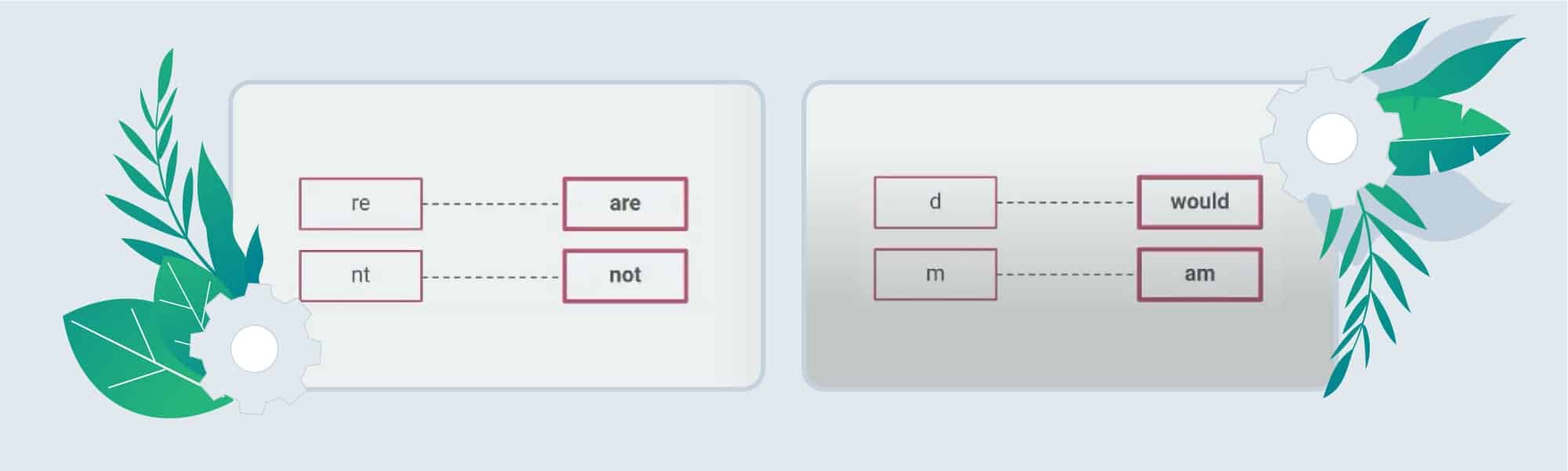
4. Decontraction is the process of transition from short forms to the full ones in order to unify them. E.g.
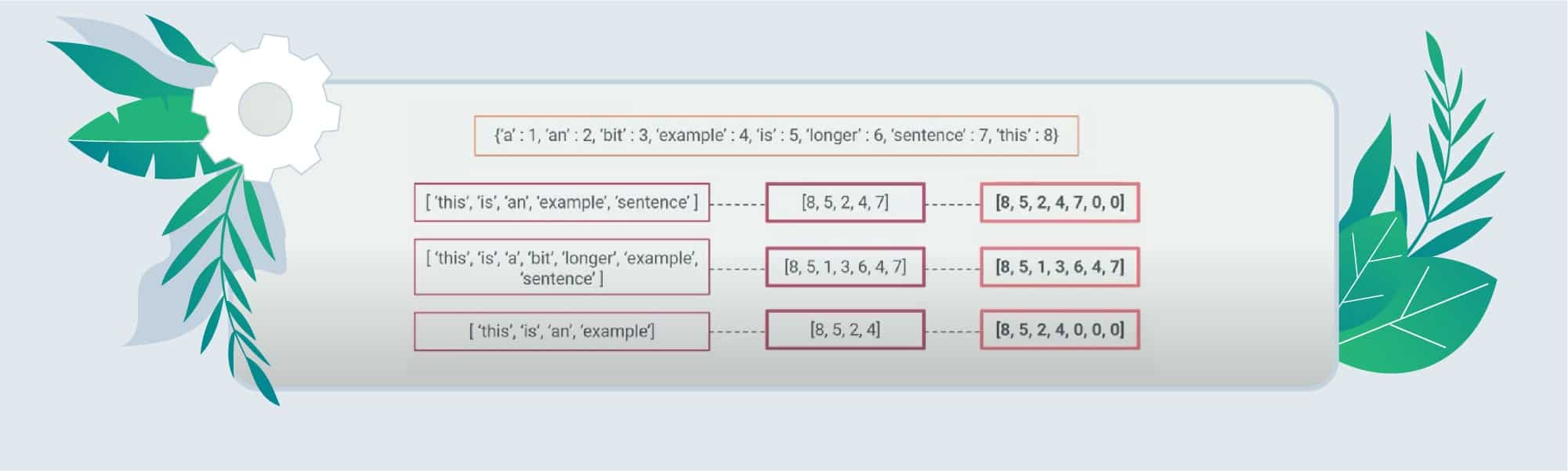
5. Text to sequences. The team used a method of Tensorflow tokenizer to create a dictionary of all used words and labeled them. E. g.

6. Padding is the process of replacement of the missing words with 0
As we mentioned before, one of the machine learning project ideas was to create a model that makes year predictions by author and label as well. To reach accurate predictions, the team tried different approaches.
The first model:

In the second model, the team changed encoding what led to a better result of mean absolute error.

Then an embedding layer of categorical data was added and the mean absolute error was changed again.

The team took an average result of embedded text data and embedded categorical data, so the result was 22 years.

As the result, the final structure looked like this:

Car price predictor
This was one of the most innovative ML projects. The goal was to predict car prices based on the image and/or other information about the car. The project itself went through most major stages of the ML pipeline: data collection, data cleaning, data analysis, model selection, model training, and preparing the model for deployment.
Data was collected from the source by web scraping using the Beautiful Soup library. Collected data include an image, brand, model, price, mileage, fuel type, transmission type, the year, the car was made. A total of over 15 000 pages were scraped and info was collected from about 146 814 cars.

Sample of collected data
Images cleaning included the process of filtering out images from the dataset that are not car exterior was used pre-trained VGG16 model, which was fine-tuned on a subset of data (64 car images and 64 not car images)
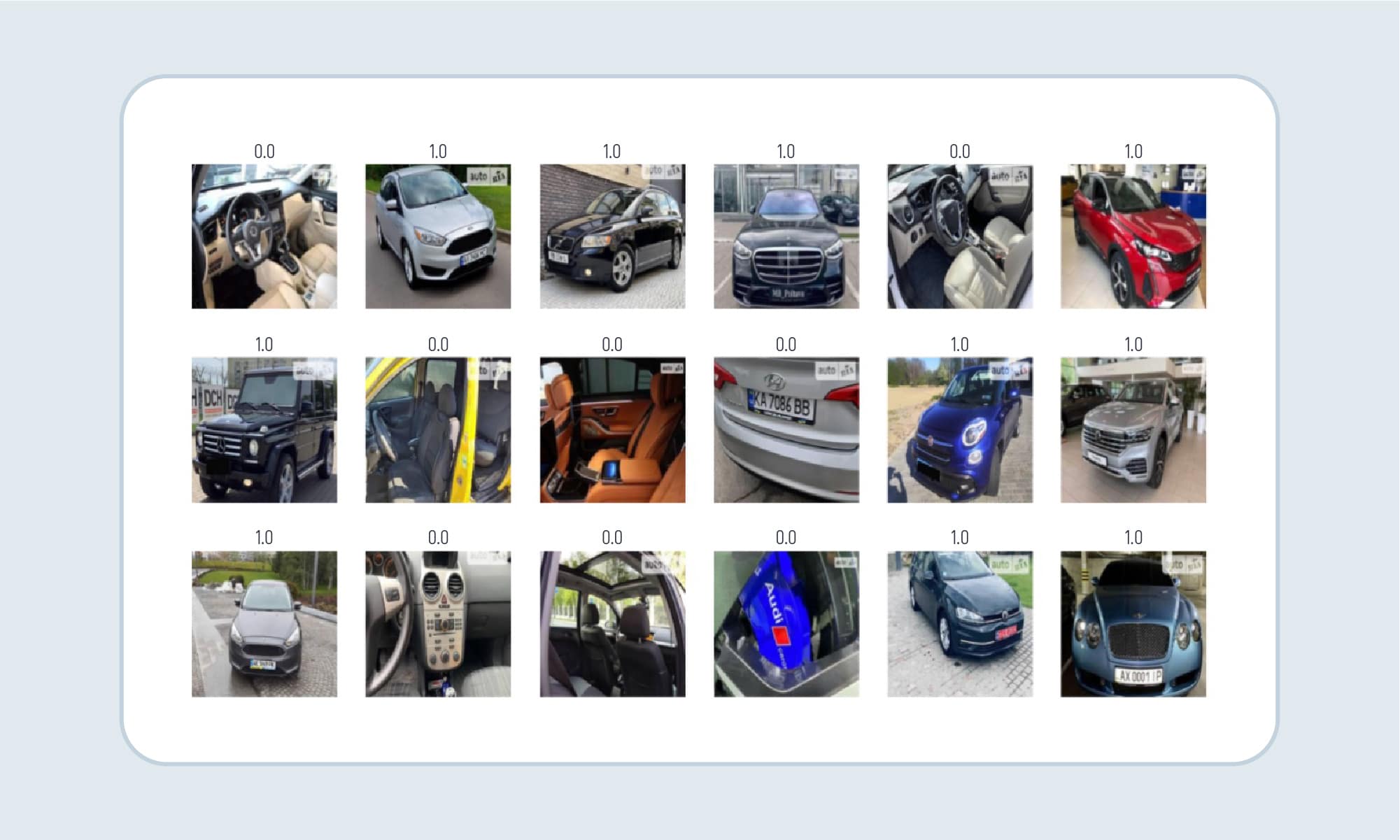
To train a model you need the images with the outer (external) look of the whole machine the images where the interior or the separate part is named “not car images” So in the example, you can see correct classifications – green, incorrect – red.
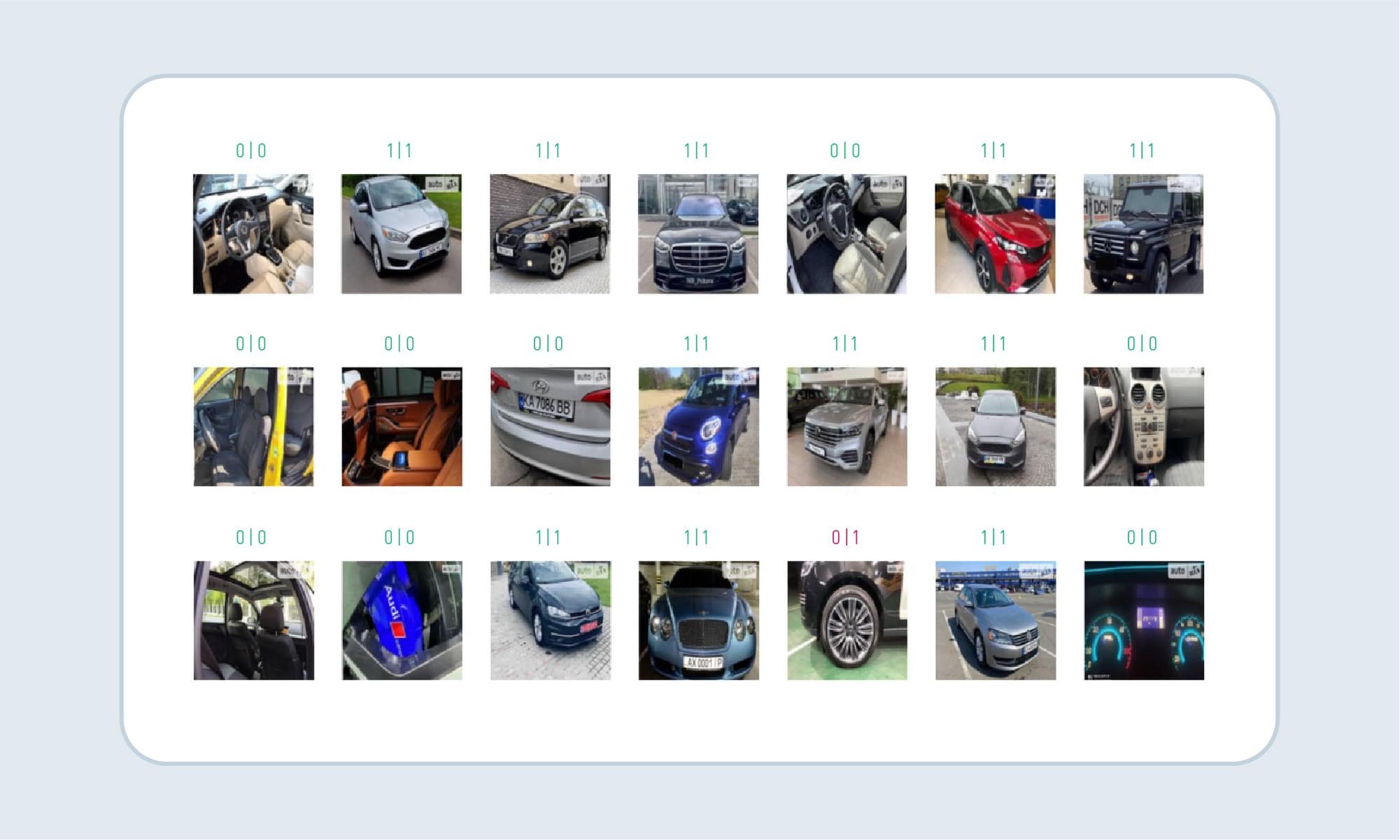
The example of images that were classified as “not car” and removed from the dataset.

Model training
Most popular ML algorithms were applied for tabular data. Metric used – mean absolute error (MAPE) Baseline – one-parameter model (return median for all inputs) Baseline mape – 74% (all that gives lower result means it is useful).
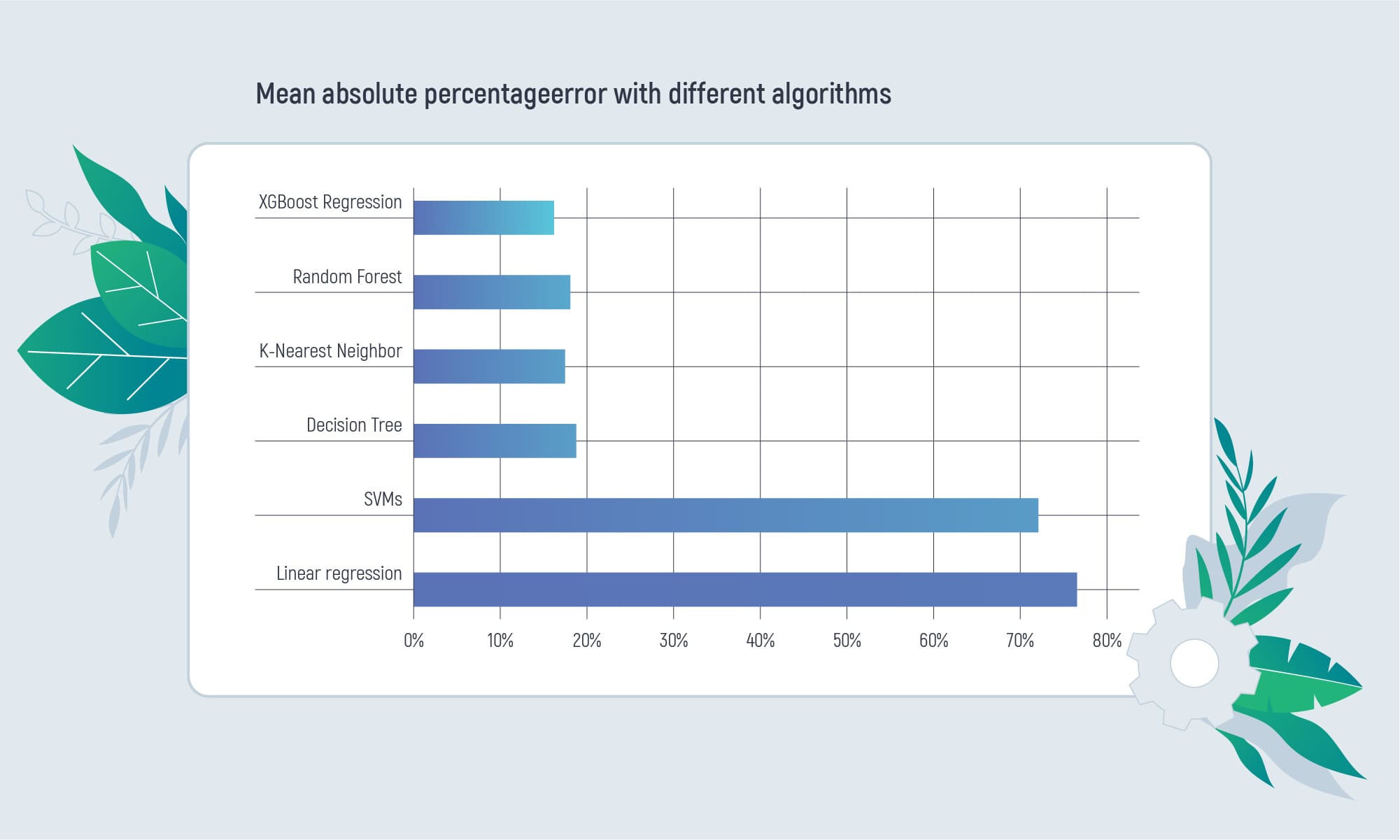
The best results for car price prediction based on the image were achieved using the pre-trained VGG16 model (MAPE = 35 %).
Model predictions
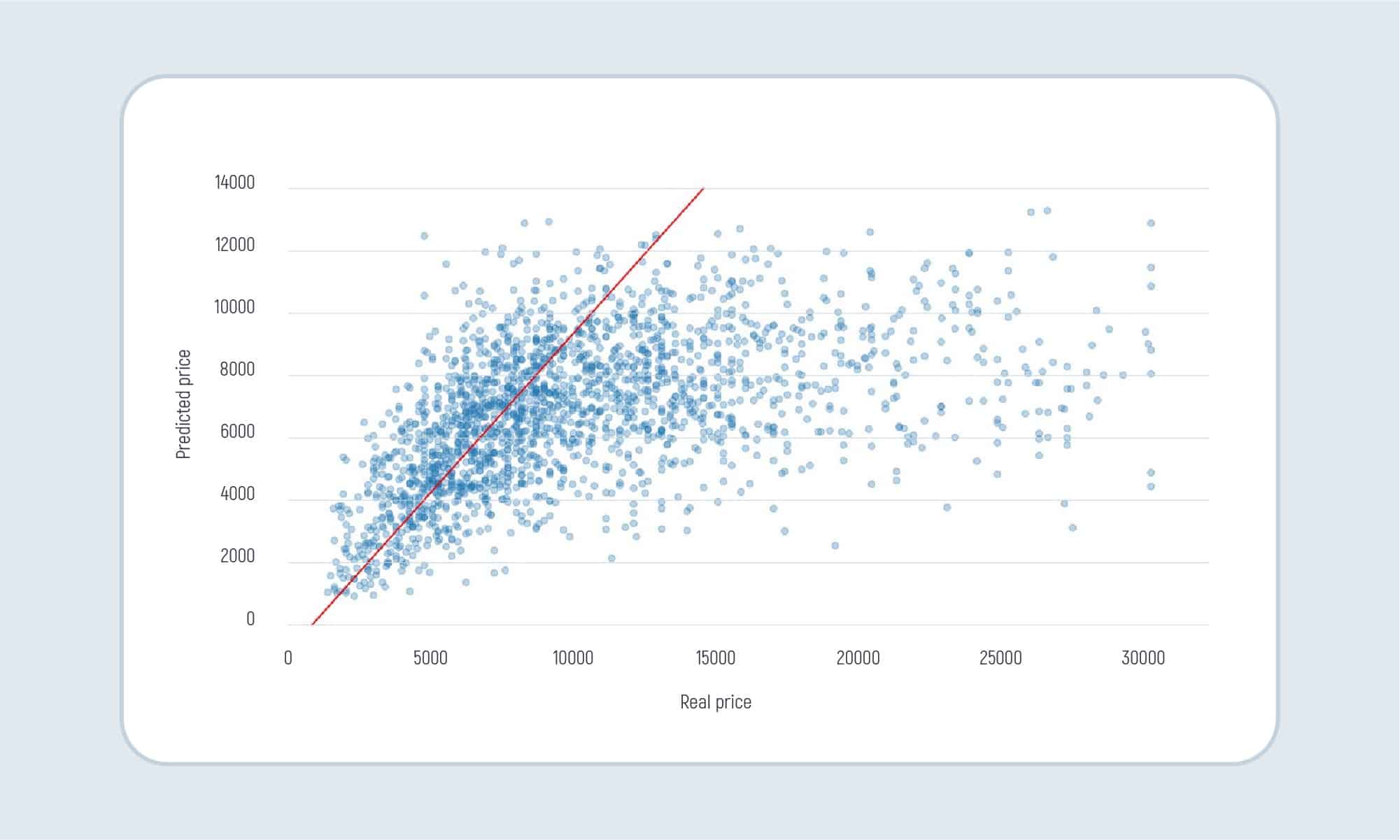
Predicted vs real price
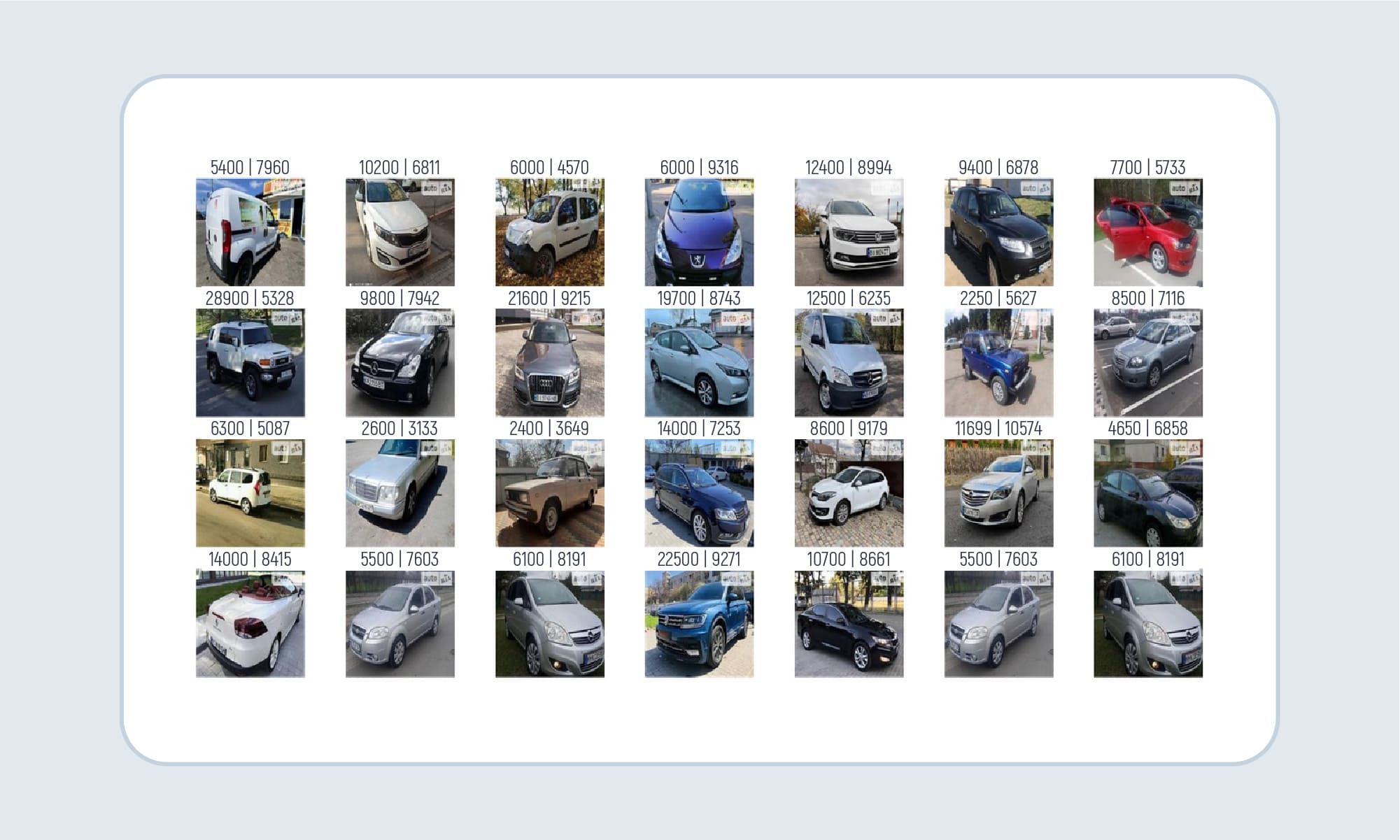
Real price vs Predicted price
Inspiring Machine Learning Projects
Inoxoft is a software development company offering clients from the USA, Canada, Israel, Norway, and other countries our big data analytics services that can help to get valuable insights from data and apply effective solutions or to produce interesting machine learning projects.
Our team has expertise in
- Predictive Analytics
- Sales prediction
- Pricing analytics
- Marketing optimization
- Natural Language Processing
If you search for a custom solution, hire Ukrainian software developers to receive the best quality services and enjoy pleasant results.
Learn more: How to outsource machine learning?
Conclusion
That was a list of impressive machine learning projects completed by our students who created each of these models from scratch. When it comes to improving skills and building a career in software development, we believe that it is important to turn theoretical knowledge into a practical experience by working on your own project. What’s even better is to do it with mentorship by an expert. We are so proud of all our students who did a great job with their projects!
Visit our website to get the latest news on our courses and exciting projects we are working on!



