

Digitalization made big data an integral part of many industries. To process large amounts of information easier, big data frameworks are used. However, choosing the right one is a challenge, as there are so many options in the market. Moreover, each business has its own needs.
Out of many big data frameworks, Spark and Hadoop MapReduce are considered among the best. In 2023, they are still in high demand, being praised by the users. Spark and Hadoop are favored by developers, as they allow distributed processing of the huge amounts of data.
This guide will tell you everything you need to know about the difference between MapReduce and Spark, their similarities, and the benefits of each framework. If you are interested, keep on reading!



- Why Big Data Frameworks Are Crucial
- What is Hadoop MapReduce?
- What is Apache Spark?
- Comparing Spark and Hadoop MapReduce: Differences
- Spark vs MapReduce: Performance
- Spark vs Hadoop MapReduce: Ease of use
- Hadoop MapReduce vs Spark: Data processing
- Spark vs MapReduce: Security
- Similarities between Spark and MapReduce
- Hadoop MapReduce vs Spark: Cost
- Apache Spark vs Hadoop MapReduce: Compatibility
- Hadoop MapReduce vs Apache Spark: Failure Tolerance
- When Does Using MapReduce Make Sense?
- Processing large datasets
- Storing data in various formats
- Advanced data processing capabilities
- When Choose Apache Spark?
- Data Streaming
- Machine Learning
- Interactive queries
- Data Management Trends
- MapReduce or Spark: What to Choose?
- Harness the Power of the Most Suitable Big Data Framework with Inoxoft
- Final Thoughts

Why Big Data Frameworks Are Crucial
Big data frameworks play a crucial role in dealing with the massive and continuously growing volume of data. Let’s discuss why they are essential because they:
- scale horizontally, allowing resource addition as data grows, while traditional databases can’t handle massive data volume.
- use distributed computing to break tasks into smaller pieces, speeding up analysis with parallel processing.
- handle various data types (structured, unstructured, semi-structured) for versatile applications.
- support real-time and batch processing, allowing companies to analyze data as it’s generated or perform batch processing for historical analysis.
- ensure data processing continuity with fault tolerance mechanisms.
- offer extensive tool ecosystems for data processing tasks.
- integrate with cost-effective storage like Hadoop Distributed File System (HDFS).
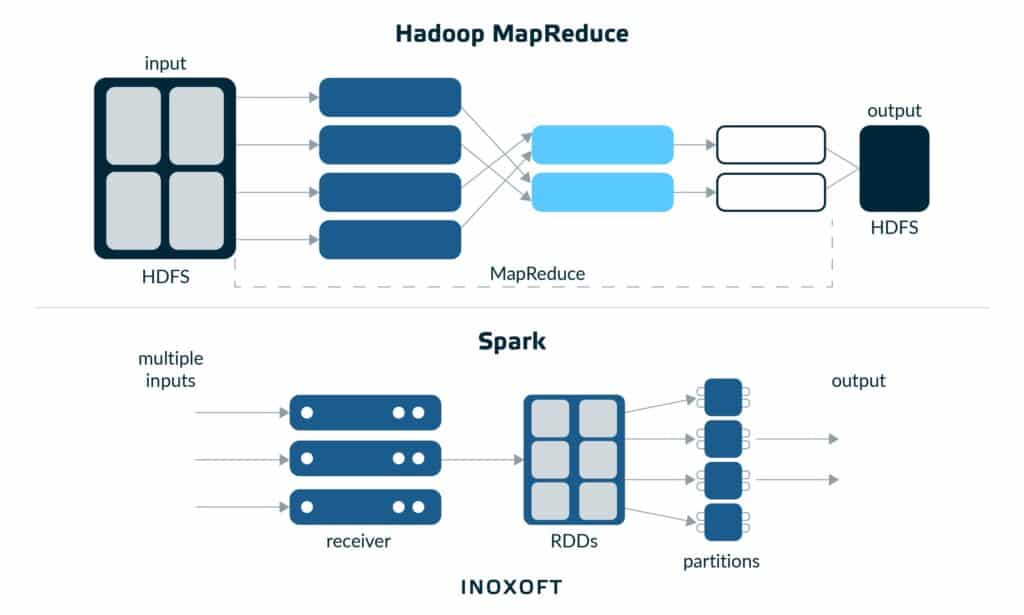
What is Hadoop MapReduce?
Before comparing Spark and Hadoop MapReduce, it’s important to learn more about each of these big data tools. Let’s start with Hadoop MapReduce.
Apache Hadoop is a collection of open-source software utilities that facilitates using a network of many computers to solve problems involving massive amounts of data and computation. Hadoop MapReduce is a software framework for easily writing applications that process vast amounts of data in parallel on large clusters of commodity hardware in a reliable, fault-tolerant manner. MapReduce was developed in 2004 by Jeffery Dean and Sanjay Ghemawat, while Hadoop was created in 2005 Doug Cutting and Mike Carafella.
The name of MapReduce reflects its two main tasks. MapReduce is well-suited for iterative computations involving large amounts of data that necessitate parallel data processing. It uses a parallel algorithm on Hadoop cluster to process data sets.
Hadoop MapReduce is used for data analysis, fraud detection, genetic algorithms, resource planning, scheduling problems, etc. It is popular among e-commerce companies such as Amazon, Walmart, and eBay. With the help of Hadoop, these companies analyze buying behavior. Also, Mapreduce is used to evaluate information on social media platforms, such as Linkedin, Facebook, and Twitter. Entertainment companies, such as Netflix, also choose Hadoop to analyze the online behavior of their customers.
What is Apache Spark?
Apache Spark is an open-source, distributed processing system used for big data workloads. It was founded in 2009 at UC Berkeley AMPLab. It started out as a research project, and it became an open source tool in 2010.
Spark focuses on machine learning, real-time workloads and interactive query. It is capable of distributing data processing tasks across multiple computers. Apache Spark is often used for processing streaming data and fog computing.
Apache Spark is in high demand in the market. More than 1000 organizations use this framework in their production, some of them are mentioned here.
Many industries choose to work with Spark. Here is how each of them uses this framework:
- The banking industry uses Spark to recommend new financial products and predict future trends.
- In healthcare, Spark is essential for recommending patient treatment and building comprehensive patient care.
- Also, Apache Spark is used in manufacturing: it recommends the right time to do preventive maintenance and eliminates the downtime of internet-connected equipment.
- The retail industry chooses Spark to attract and keep customers by leveraging the power of big data analytics. Retailers also use Apache Spark to analyze customer data to identify patterns in their behavior.
Now let’s proceed to Spark vs Hadoop MapReduce comparison.
Comparing Spark and Hadoop MapReduce: Differences

Before choosing between Spark and Hadoop MapReduce, it’s important to consider what sets these data processing frameworks apart. Each of these tools has its pros and cons. Now it’s time to discover the difference between Spark and Hadoop MapReduce.
Spark vs MapReduce: Performance
The first thing you should pay attention to is the frameworks’ performances. Hadoop MapReduce persists data back to the disc after a map or reduces operation, while Apache Spark persists data in RAM, or random access memory. For smaller workloads, Spark’s data processing speeds are up to 100x faster than MapReduce. The data you use for Hadoop isn’t meant to fit in the memory, so other services can coexist with MapReduce.
Spark vs Hadoop MapReduce: Ease of use
One of the main benefits of Spark is that it has pre-built APIs for Python, Scala and Java. Spark has simple building blocks, that’s why it’s easier to write user-defined functions. Using Hadoop, on the other hand, is more challenging. MapReduce doesn’t have an interactive mode, while Spark does. However, there are a couple of tools to make Hadoop MapReduce easier to use, for instance, Apache Impala or Apache Tez.
Hadoop MapReduce vs Spark: Data processing
Spark is good at real-time processing and batch processing. Thus, you don’t have to split tasks across multiple platforms. It uses in-memory caching and optimized query execution to provide quick results when running queries against any amount of data. Hadoop MapReduce, on the other hand, is more suitable for batch processing. By dividing petabytes of data into smaller chunks and working them in parallel on Hadoop commodity computers, MapReduce makes concurrent processing easier.
Spark vs MapReduce: Security
MapReduce is more advanced when it comes to security in comparison with Spark. It’s because security in Spark is by default turned off, so it cannot deal with possible attacks. Spark enhances security with authentication via shared secret or event logging, whereas Hadoop uses multiple authentications and access control methods. Though overall, Hadoop is more secure, Spark can integrate with Hadoop to reach a higher security level. Hadoop, however, has its default security benefits and also can be integrated with Hadoop security projects. Apache Hadoop MapReduce is more secure because of Kerberos and it also supports Access Control Lists (ACLs) which are a traditional file permission model.
Similarities between Spark and MapReduce
As you can see, Spark and MapReduce are both popular nowadays. Of course, there are things that both of these frameworks share. Before choosing what is better, Spark or Hadoop MapReduce, let’s analyze their common features.
Hadoop MapReduce vs Spark: Cost
MapReduce and Spark are both open-source solutions, and such software typically is free. However, you still have to spend money on staff and machines. One more common feature of Spark and MapReduce is that both of these frameworks can run on the cloud and use commodity servers. But if you need to process large amounts of data, Hadoop will be more cost-effective, because hard disk space is cheaper than memory space.
Apache Spark vs Hadoop MapReduce: Compatibility
Both Spark and Hadoop are compatible with different types of data and data sources. Moreover, Spark can run in the cloud or be a standalone application. The same file formats and types of data can be integrated with Hadoop and Spark, because data sources that use the Hadoop Input format are supported by Spark.
Hadoop MapReduce vs Apache Spark: Failure Tolerance
One more thing that unites Spark and Hadoop MapReduce is that they both have retries per task and speculative execution. Still, Spark relies on RAM and MapReduce relies on hard drives more. It gives MapReduce an additional advantage because it’s more secure in case something goes wrong during the execution. If the process stops in the middle, you can continue from where you left.
When Does Using MapReduce Make Sense?
If you gravitate towards Hadoop MapReduce, you should know the cases where it is the most efficient.
Processing large datasets
When businesses deal with enormous datasets measured in petabytes or terabytes, MapReduce becomes an attractive choice. It offers a scalable solution, allowing companies to distribute data processing tasks across multiple nodes or servers. This parallel processing approach accelerates the analysis of colossal datasets.
Moreover, MapReduce’s fault tolerance mechanisms ensure that processing continues even if a hardware failure occurs, improving reliability.
Storing data in various formats
MapReduce is the proper framework for companies dealing with diverse data formats. Whether text, images, or plain text, MapReduce can efficiently process and analyze these various data types.
One of the significant advantages of using MapReduce for such tasks is its ability to handle large files that cannot fit entirely in memory. MapReduce dives these large files into smaller, manageable chunks, reducing memory requirements and making processing more cost-effective.
Advanced data processing capabilities
MapReduce offers robust capabilities for performing a wide range of data processing tasks. This includes basic (summarization, filtering, and joining of extensive data sets) and complex analyses. Its disk-based storage approach, instead of in-memory processing, is particularly advantageous when dealing with massive data volumes.
Additionally, MapReduce’s customizable map and reduce functions enable companies to tailor their data processing tasks to the specific needs and structures of their data.
When Choose Apache Spark?
What about Apache Spark? We’ve prepared its use cases to help you understand the Spark and MapReduce difference.
Data Streaming
As businesses embrace digital transformation, real-time data analysis is crucial. Apache Spark’s in-memory processing, including Spark Streaming, supports this need:
- Streaming ETL (Extract, Transform, Load) in Spark enhances efficiency. Data is continuously cleaned and aggregated in memory before being saved to the target data store. Thus, it reduces the costs associated with ETL and accelerates data availability for analysis, improving time-to-insight.
- By combining real-time data with static data sources, companies can create a comprehensive customer profile, personalizing customer experiences. This way, you enhance brand awareness, increase conversions, and boost sales. With a 360-degree client view, you can fine-tune marketing campaigns and cross-promotion.
- Spark Streaming enables companies to analyze data in real time, identifying unusual activities that require immediate attention. For instance, businesses can detect trends and patterns in data that might pose a threat to their operations and take prompt corrective actions.
Machine Learning
Apache Spark’s Machine Learning Library (MLlib) offers a robust set of tools for predictive analysis. Companies can use machine learning to perform customer segmentation for more targeted marketing. With its help, you can personalize interactions and improve customer engagement.
Sentiment analysis helps reveal valuable insights into customers’ thoughts about a brand or its products. Use this information to adjust strategies and enhance client satisfaction.
Interactive queries
Users can query data streams without persisting it to an external database, which frees up time and resources. This real-time data analysis can be invaluable for making on-the-fly decisions and gaining insights into evolving datasets without the delay of traditional query processes.
Data Management Trends
Companies should evolve to stay competitive — and data management isn’t an exception. Here are some trends in this domain worth paying attention to:
- XOps. This is an umbrella term used to describe various IT operations such as DevOps, AIOps, MLOps, DevSecOps, and BizDevOps. XOps aims to enhance reliability and reusability in data management processes. It emphasizes efficient and automated practices to ensure the smooth flow of data operations.
- Data Fabric. Data Fabric is an architectural framework designed to create a unified and seamless data management platform. It combines various data storage, analytics, processing, and security components. As a result, companies manage data more cohesively.
- Data analytics as a core business function. Traditionally, data management and analytics were the responsibility of specialized teams. But today, it has become a fundamental business function where decision-makers within a company have direct access to data. This way, they make decisions more swiftly and effectively.
MapReduce or Spark: What to Choose?
The choice between MapReduce and Spark depends on your specific business use case and requirements.
Apache Spark:
- Spark is known for its excellent performance, primarily due to in-memory data processing capabilities. Additionally, it can lead to cost savings, reducing the need for extensive disk I/O.
- Spark is compatible with all of Hadoop’s data sources and file formats, making it a smart choice for organizations already invested in this ecosystem.
- Spark provides user-friendly APIs for multiple programming languages. That means a faster learning curve than other big data frameworks.
- Spark has additional features like built-in graph processing and machine learning libraries. This allows companies to address a wider variety of data-processing tasks.
Hadoop MapReduce:
- Hadoop MapReduce is a more mature platform, having been purpose-built for batch processing. It excels in scenarios where batch processing is the primary data processing requirement.
- MapReduce efficiently processes and analyzes data that exceeds memory capacity. This way, it is more cost-effective than Spark for extremely large data sets.
- MapReduce has been in the industry longer, which means a larger pool of professionals with experience in this technology.
- The MapReduce ecosystem is extensive, with many supporting projects, tools, and cloud services. It offers a comprehensive solution for various data processing needs.
It’s essential to note that, in many cases, if you choose Spark, it doesn’t operate in isolation. You may still need components of the Hadoop ecosystem, such as HDFS for data storage and potentially Apache Hive, HBase, Pig, or Impala for specific data processing tasks.
That means you might run both Hadoop (including MapReduce) and Spark to create a comprehensive big-data solution tailored to your specific requirements.
Anyway, the choice between MapReduce and Spark ultimately depends on your data size, processing needs, existing ecosystem, and availability of skilled personnel.
Harness the Power of the Most Suitable Big Data Framework with Inoxoft
Inoxoft is a software development company that has been offering digitizing services for seven years, working with clients worldwide. For their projects, our customers can rely on a personalized approach, a competent staff, and professionals who are always full of innovative ideas. We create engineering teams to offer top-notch software products, allowing organizations, enterprises, and businesses to expand more quickly with the appropriate people on board.
If you need to structure your data and use it for the benefit of your business, you should use our big data development services. Inoxoft extracts valuable insights from data and applies effective solutions on strategic, operational, and tactical levels.
Our company will tell you everything you need to know about big data challenges and solutions. We will help you reduce possible issues by collecting and analyzing relevant data, securing your data, and hiring professionals.
Final Thoughts
What is the difference between MapReduce and Spark? Simply put, Spark has excellent performance, while MapReduce is more mature and cost-effective for large datasets. Often, they work together. You should adapt your choice to your use cases, existing infrastructure, and team skills.
In this guide, we helped you choose between Spark and Hadoop MapReduce. However, each situation is unique, and you may need professional assistance. Contact Inoxoft to choose the ultimate software framework and reach your business goals.
Frequently Asked Questions
When to use MapReduce vs Spark?
Comparing Spark and MapReduce, Spark is the better choice when you need fast processing or when data needs to be processed more than once. MapReduce is more suitable for processing large amounts of data, and it is a good economical solution.
Why is Spark faster than MapReduce?
Spark and MapReduce vary primarily in that Spark processes data in memory and keeps it there for following steps while MapReduce processes data on storage. As a result, Spark's data processing speeds are up to 100 times quicker than MapReduce's for lesser workloads.
What is the main difference between MapReduce and Spark?
MapReduce is a programming model developed by Google for processing large amounts of data in parallel across multiple nodes in a cluster. Spark, on the other hand, is a general-purpose distributed computing framework designed to be faster and more flexible than MapReduce.



